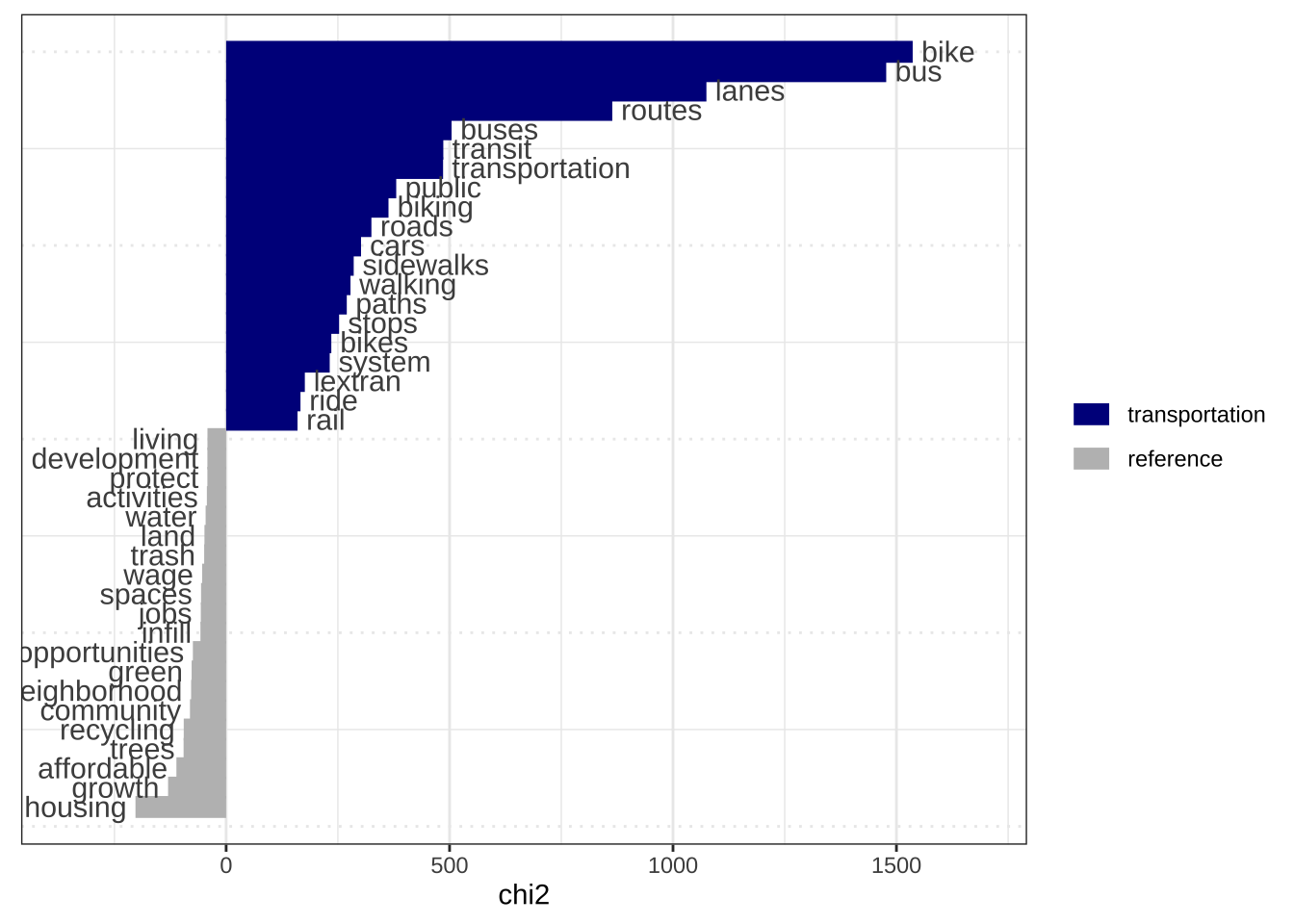
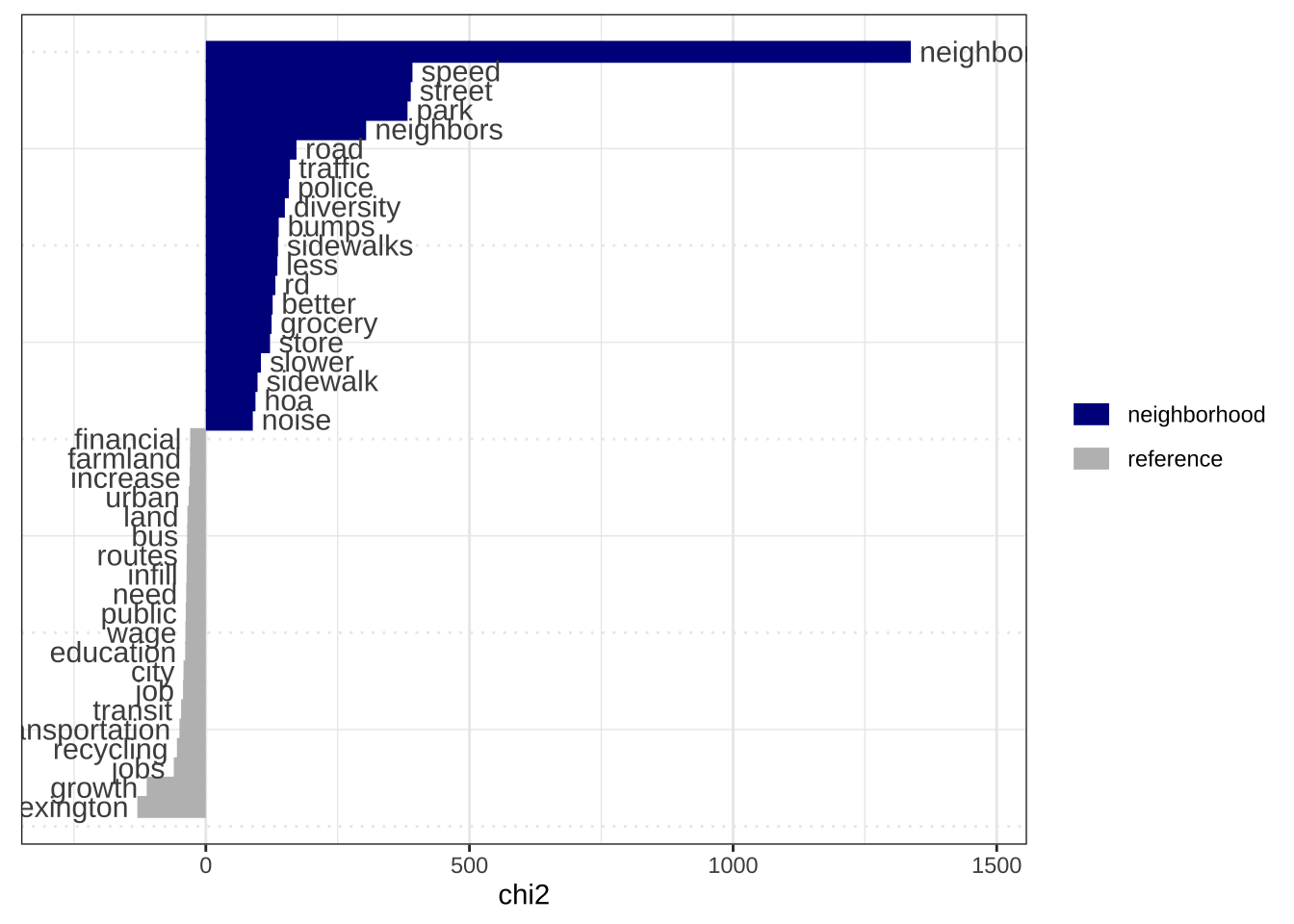
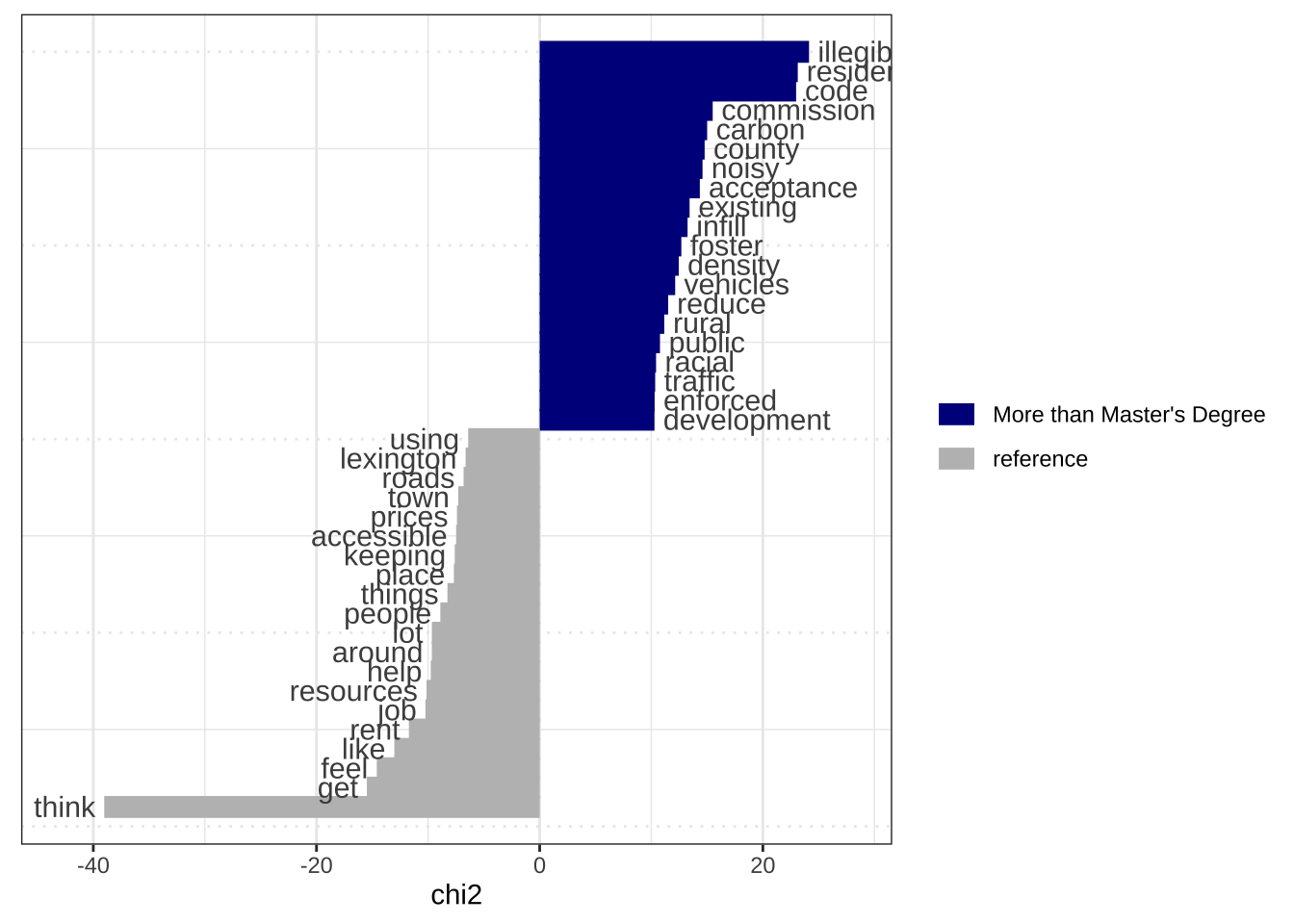
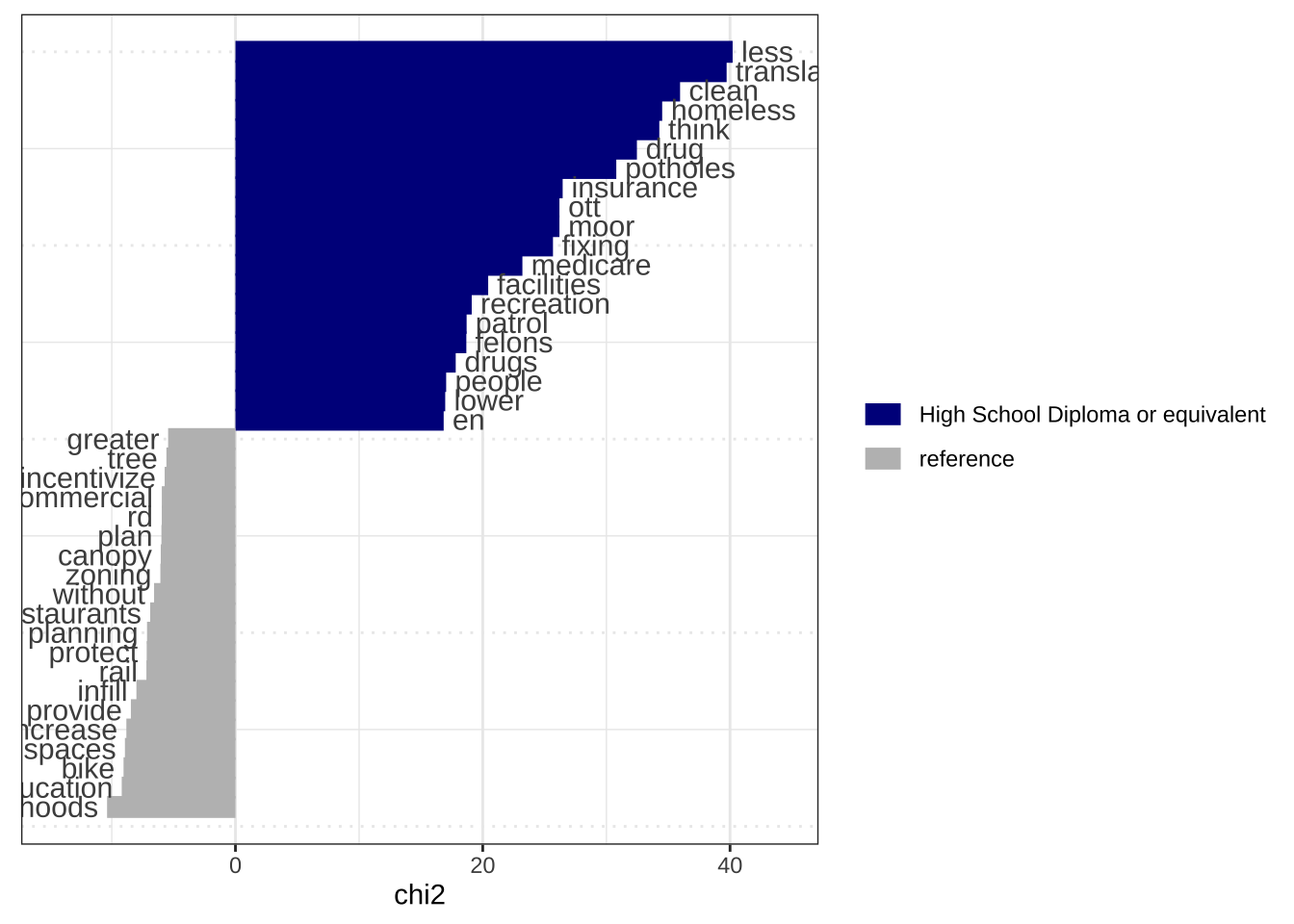
if(!require(here)){
install.packages("here")
library(here)
}Loading required package: herehere() starts at /Users/joseffruehwald/Documents/AS500_siteif(!require(fs)){
install.packages("fs")
library(fs)
}Loading required package: fsif(!require(janitor)){
install.packages("janitor")
library(janitor)
}Loading required package: janitor
Attaching package: 'janitor'The following objects are masked from 'package:stats':
chisq.test, fisher.testif(!require(quanteda.textplots)){
install.packages("quanteda.textplots")
library(quanteda.textplots)
}Loading required package: quanteda.textplots