if(!require(tm)){
install.packages("tm")
library(tm)
}
if(!require(lsa)){
install.packages("lsa")
library(lsa)
}
if(!require(quanteda)){
install.packages("quanteda")
library(quanteda)
}
if(!require(quanteda.textstats)){
install.packages("quanteda.textstats")
library(quanteda.textstats)
}
if(!require(quanteda.corpora)){
remotes::install_github("quanteda/quanteda.corpora")
library(quanteda.corpora)
}
if(!require(quanteda.tidy)){
remotes::install_github("quanteda/quanteda.tidy")
library(quanteda.corpora)
}
if(!require(rainette)){
install.packages("rainette")
library(rainette)
}
if(!require(GGally)){
install.packages("GGally")
library(GGally)
}Setup
New Install
Loading
Prepping data
frank <- gutenberg_download(84)
frank |>
mutate(
text = str_squish(text),
section = case_when(
str_detect(text, "^Letter \\d+$") ~ text,
str_detect(text, "^Chapter \\d+$") ~ text
)
) |>
fill(section) |>
filter(text != section,
!is.na(section),
str_length(text) > 0) ->
frankenstein
frankenstein |>
unnest_tokens(
word,
text,
token = "words"
) |>
mutate(word = str_remove_all(word, "_"))->
frank_tokensfrank_tokens |>
slice(1:50) |>
rmarkdown::paged_table()The quanteda-Verse
While tidytext is part of the larger “tidytext” universe, there is also another -verse of packages for analyzing text in R, the quanteda-verse.
Quanteda corpus
summary(data_corpus_inaugural, n = 10)Corpus consisting of 59 documents, showing 10 documents:
Text Types Tokens Sentences Year President FirstName
1789-Washington 625 1537 23 1789 Washington George
1793-Washington 96 147 4 1793 Washington George
1797-Adams 826 2577 37 1797 Adams John
1801-Jefferson 717 1923 41 1801 Jefferson Thomas
1805-Jefferson 804 2380 45 1805 Jefferson Thomas
1809-Madison 535 1261 21 1809 Madison James
1813-Madison 541 1302 33 1813 Madison James
1817-Monroe 1040 3677 121 1817 Monroe James
1821-Monroe 1259 4886 131 1821 Monroe James
1825-Adams 1003 3147 74 1825 Adams John Quincy
Party
none
none
Federalist
Democratic-Republican
Democratic-Republican
Democratic-Republican
Democratic-Republican
Democratic-Republican
Democratic-Republican
Democratic-RepublicanBeing “tidy”
There is some “tidy” support for quanteda objects
Corpus consisting of 59 documents, showing 10 documents:
Text Types Tokens Sentences Year President FirstName
1789-Washington 625 1537 23 1789 Washington George
1793-Washington 96 147 4 1793 Washington George
1797-Adams 826 2577 37 1797 Adams John
1801-Jefferson 717 1923 41 1801 Jefferson Thomas
1805-Jefferson 804 2380 45 1805 Jefferson Thomas
1809-Madison 535 1261 21 1809 Madison James
1813-Madison 541 1302 33 1813 Madison James
1817-Monroe 1040 3677 121 1817 Monroe James
1821-Monroe 1259 4886 131 1821 Monroe James
1825-Adams 1003 3147 74 1825 Adams John Quincy
Party decade
none 1780
none 1790
Federalist 1790
Democratic-Republican 1800
Democratic-Republican 1800
Democratic-Republican 1800
Democratic-Republican 1810
Democratic-Republican 1810
Democratic-Republican 1820
Democratic-Republican 1820data_corpus_inaugural |>
slice(1:10)Corpus consisting of 10 documents and 4 docvars.
1789-Washington :
"Fellow-Citizens of the Senate and of the House of Representa..."
1793-Washington :
"Fellow citizens, I am again called upon by the voice of my c..."
1797-Adams :
"When it was first perceived, in early times, that no middle ..."
1801-Jefferson :
"Friends and Fellow Citizens: Called upon to undertake the du..."
1805-Jefferson :
"Proceeding, fellow citizens, to that qualification which the..."
1809-Madison :
"Unwilling to depart from examples of the most revered author..."
[ reached max_ndoc ... 4 more documents ]data_corpus_inaugural |>
filter(Year >= 1960, Year <= 1980)Corpus consisting of 5 documents and 4 docvars.
1961-Kennedy :
"Vice President Johnson, Mr. Speaker, Mr. Chief Justice, Pres..."
1965-Johnson :
"My fellow countrymen, on this occasion, the oath I have take..."
1969-Nixon :
"Senator Dirksen, Mr. Chief Justice, Mr. Vice President, Pres..."
1973-Nixon :
"Mr. Vice President, Mr. Speaker, Mr. Chief Justice, Senator ..."
1977-Carter :
"For myself and for our Nation, I want to thank my predecesso..."Tidy to Quanteda
frankenstein |>
mutate(text = str_remove_all(text, "_")) |>
group_by(section) |>
summarise(text = str_flatten(text, collapse = " ")) |>
# quanteda::corpus,
# so we need to quote column names
corpus(
docid_field = "section",
text_field = "text"
)->
frank_corpusfrank_corpus |>
summary(n = 4)Corpus consisting of 28 documents, showing 4 documents:
Text Types Tokens Sentences
Chapter 1 765 1955 75
Chapter 10 917 2745 129
Chapter 11 921 3309 111
Chapter 12 754 2361 90Tokenizing
quanteda tokenizing is done with quanteda::tokens()
data_corpus_inaugural |>
tokens(remove_punct = T)->
inaugural_tokensThere are also many functions to apply to tokens that are prefixed with tokens_
inaugural_tokens |>
textstat_collocations(size = 3) |>
slice(1:50) |>
rmarkdown::paged_table()Lowercasing, dropping stop words, and stemming
inaugural_tokens |>
tokens_tolower() |>
tokens_remove(pattern = stopwords()) |>
tokens_wordstem() ->
inaugural_stemDescribing documents
We’ve looked at how data points can exist along dimensions with other data.
plotting code
library(palmerpenguins)
penguins |>
select(
species,
ends_with("_mm"),
ends_with("_g")
) |>
drop_na() |>
ggpairs(aes(color = species))+
khroma::scale_color_bright()+
khroma::scale_fill_bright()+
theme(strip.text = element_text(size = 6))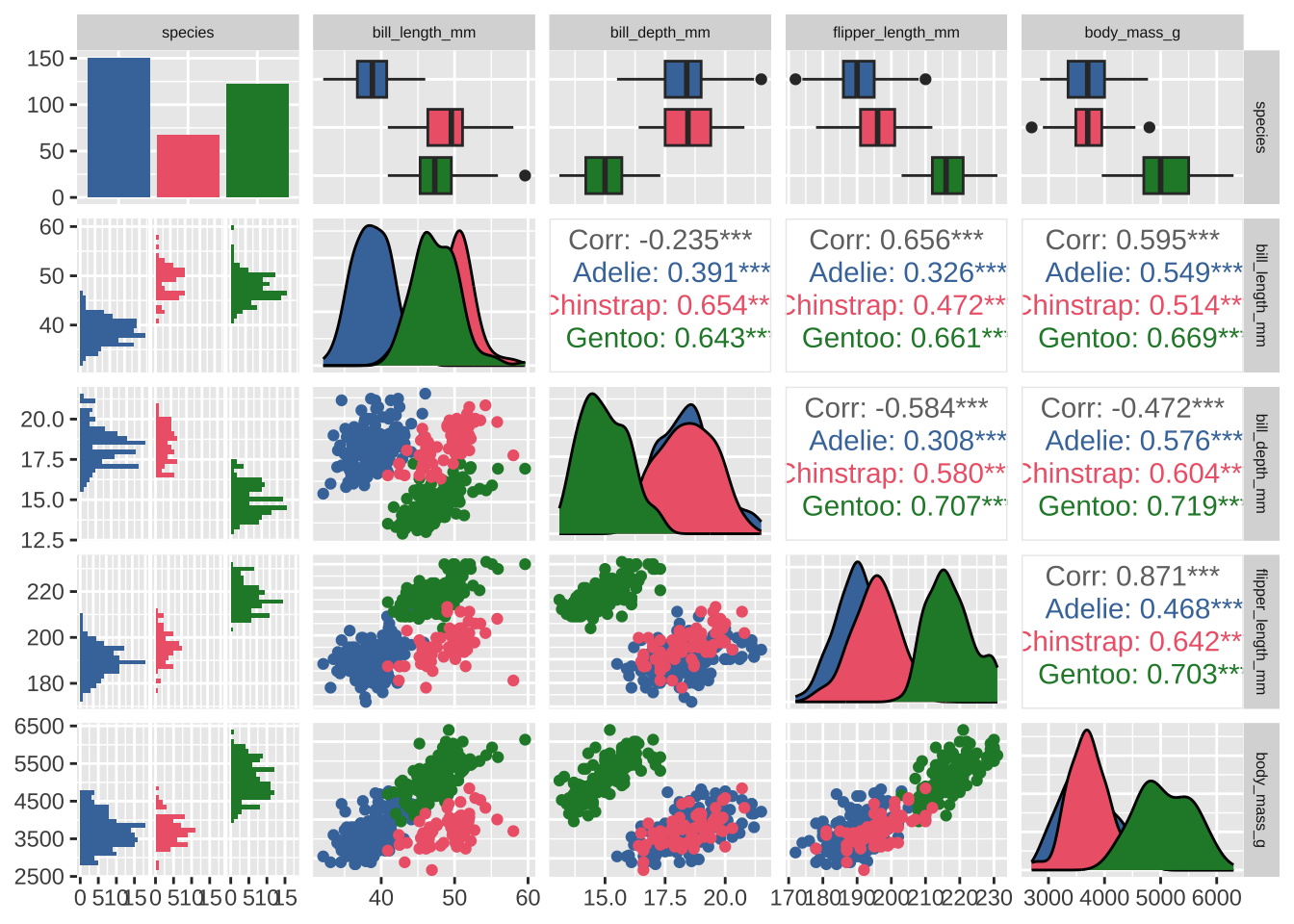
Dimensions of documents
The way fields like textmining and natural language processing have decided to give documents “dimensions” is to use the count of how often words appear inside of them to create what’s called a “document term matrix.”
frank_tokens |>
count(section, word) |>
pivot_wider(names_from = word, values_from = n) |>
select(1:30) |>
rmarkdown::paged_table()Document Term Matrix in quanteda
inaugural_stem |>
dfm() ->
inaugural_dfminaugural_dfmDocument-feature matrix of: 59 documents, 5,458 features (89.34% sparse) and 4 docvars.
features
docs fellow-citizen senat hous repres among vicissitud incid life
1789-Washington 1 1 2 2 1 1 1 1
1793-Washington 0 0 0 0 0 0 0 0
1797-Adams 3 1 3 3 4 0 0 2
1801-Jefferson 2 0 0 1 1 0 0 1
1805-Jefferson 0 0 0 0 7 0 0 2
1809-Madison 1 0 0 1 0 1 0 1
features
docs event fill
1789-Washington 2 1
1793-Washington 0 0
1797-Adams 0 0
1801-Jefferson 0 0
1805-Jefferson 1 0
1809-Madison 0 1
[ reached max_ndoc ... 53 more documents, reached max_nfeat ... 5,448 more features ]inaugural_dfm |>
dfm_tfidf()->
inaugural_tfidfinaugural_tfidfDocument-feature matrix of: 59 documents, 5,458 features (89.34% sparse) and 4 docvars.
features
docs fellow-citizen senat hous repres among
1789-Washington 0.4920984 0.624724 1.249448 0.8972654 0.1373836
1793-Washington 0 0 0 0 0
1797-Adams 1.4762952 0.624724 1.874172 1.3458982 0.5495342
1801-Jefferson 0.9841968 0 0 0.4486327 0.1373836
1805-Jefferson 0 0 0 0 0.9616849
1809-Madison 0.4920984 0 0 0.4486327 0
features
docs vicissitud incid life event fill
1789-Washington 0.9927008 0.925754 0.08065593 0.9841968 0.5947608
1793-Washington 0 0 0 0 0
1797-Adams 0 0 0.16131186 0 0
1801-Jefferson 0 0 0.08065593 0 0
1805-Jefferson 0 0 0.16131186 0.4920984 0
1809-Madison 0.9927008 0 0.08065593 0 0.5947608
[ reached max_ndoc ... 53 more documents, reached max_nfeat ... 5,448 more features ]Similarity
inaugural_tfidf |>
textstat_simil(method = "cosine") |>
as_tibble() |>
arrange(desc(cosine)) # A tibble: 1,711 × 3
document1 document2 cosine
<fct> <fct> <dbl>
1 1817-Monroe 1821-Monroe 0.367
2 1837-VanBuren 1841-Harrison 0.317
3 1841-Harrison 1845-Polk 0.302
4 2001-Bush 2021-Biden 0.292
5 1897-McKinley 1909-Taft 0.290
6 1837-VanBuren 1853-Pierce 0.289
7 1825-Adams 1845-Polk 0.289
8 1841-Harrison 1857-Buchanan 0.289
9 1845-Polk 1857-Buchanan 0.288
10 1889-Harrison 1897-McKinley 0.285
# ℹ 1,701 more rowsClustering
We can cluster over a distance matrix
inaugural_tfidf |>
textstat_dist() |>
# moving over to base R!
as.dist() |>
hclust() ->
inaugural_clust1plot(inaugural_clust1)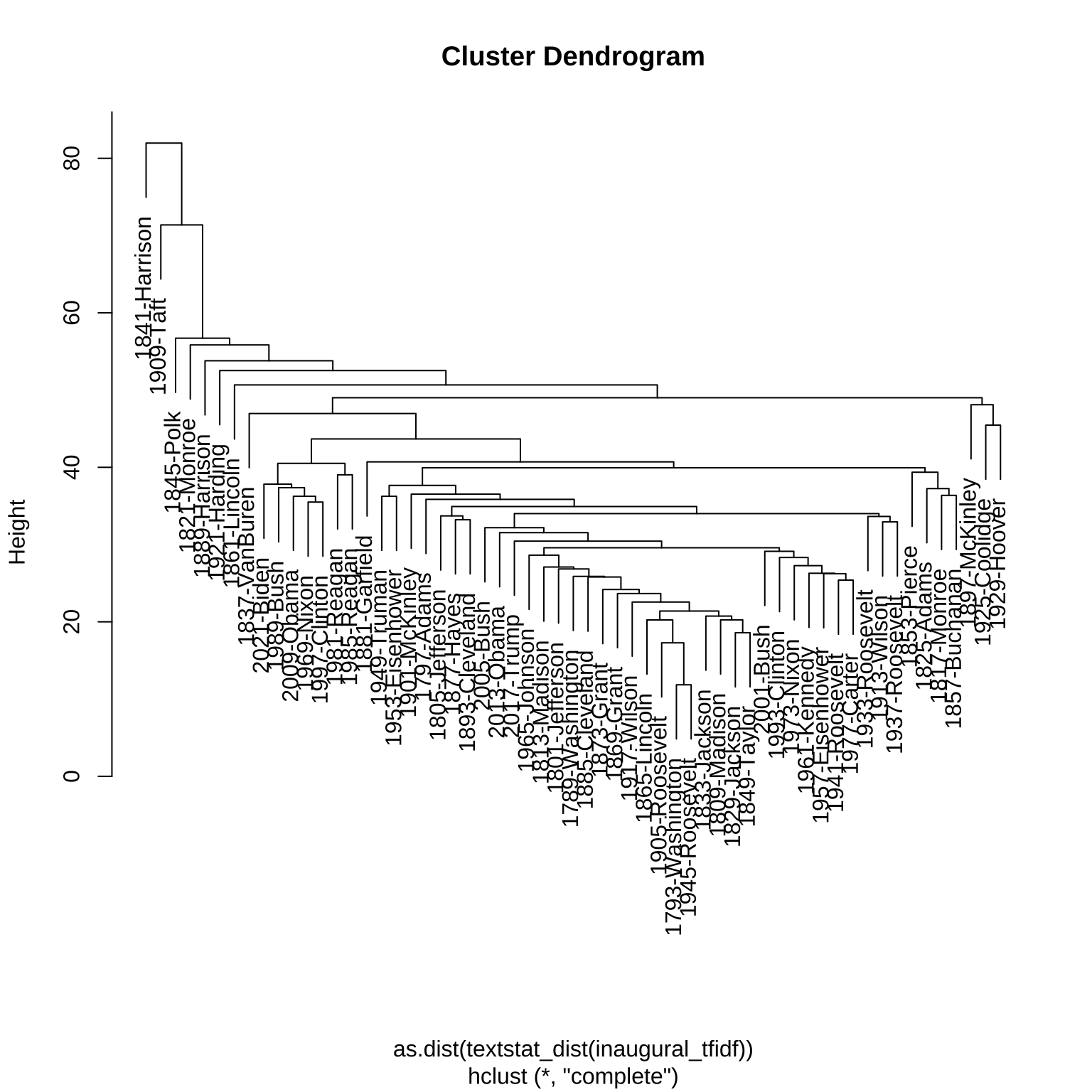
A more interactive clustering
data_corpus_inaugural |>
split_segments() ->
inaugural_corpus2
inaugural_corpus2 |>
tokens(remove_punct = T) |>
tokens_tolower() |>
tokens_remove(pattern = stopwords()) |>
tokens_wordstem() ->
inaugural_tokens2
inaugural_tokens2 |>
dfm() |>
dfm_trim(min_docfreq = 10)->
inaugural_dfm2clust2 <- rainette(inaugural_dfm2)Warning in rainette(inaugural_dfm2): some documents don't have any term, they
won't be assigned to any cluster.rainette_explor(clust2, inaugural_dfm2, inaugural_corpus2)inaugural_corpus2$group <- cutree(clust2, 5)