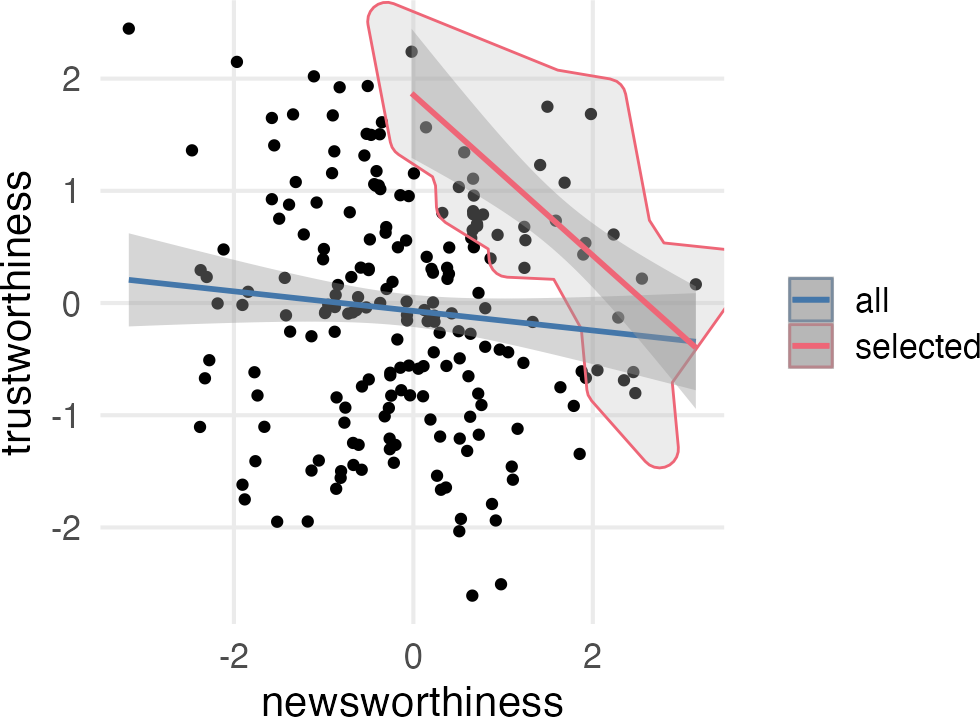
The first example in the book is about Berkson’s Paradox, which I believe is a kind of selection bias. The question is “Why do so many research results that are newsworthy seem unreliable?” The idea being that funding (or whatever, maybe “editorial decisions to publish a paper”) is based jointly on its trustworthiness and its newsworthiness.
tibble(trustworthiness =rnorm(200),newsworthiness =rnorm(200),score = trustworthiness + newsworthiness,score_percentile =ecdf(score)(score)) -> research
Figure 1: The selection effect on the (non)correation between newsworthiness and trustworthiness
Multicollinearity
In fact, there is nothing wrong with multicollinearity. The model will work fine for prediction. You will just be frustrated trying to understand it.
When I was starting to get into advanced statistical modelling during my PhD (some time around 2010?) everyone suddenly learned about multicollinearity and got freaked out about it, so this was genuinely new info to me. See also Vanhove (2021), Collinearity isn’t a disease that needs curing.
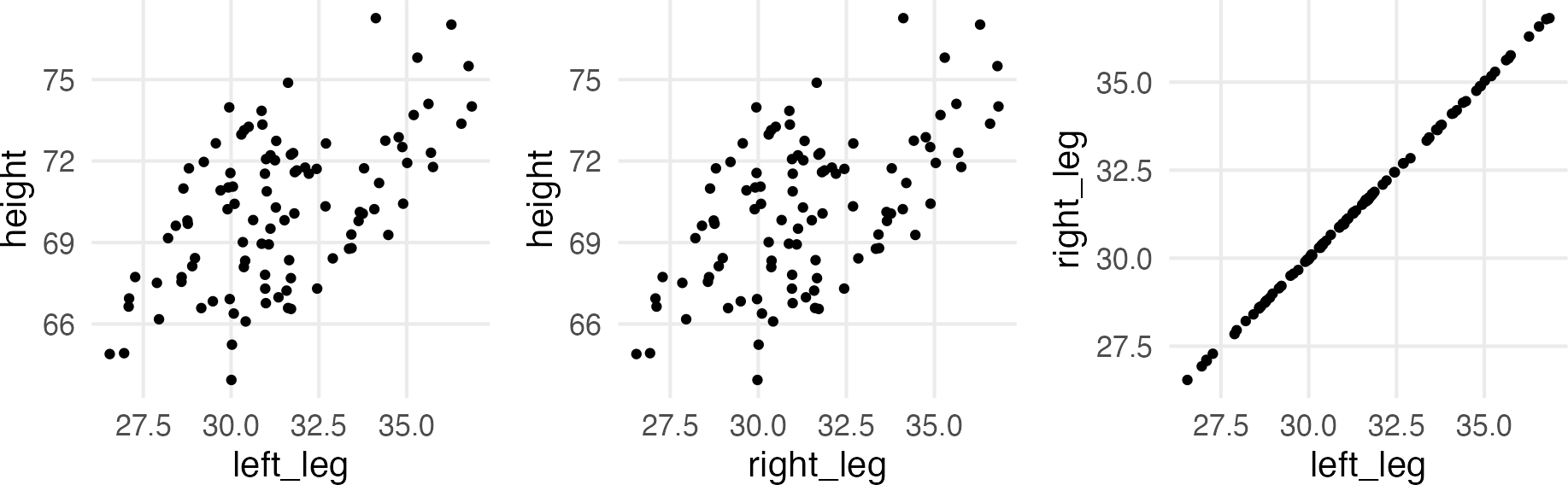
The illustration from the book was about the relationship between total body height and leg length.
leg-heigh simulation
tibble(n =100,# height in inchesheight =rnorm(n, mean =70, sd =3),# legs as a proportion of heightleg_prop =runif(n, 0.4, 0.5),left_leg = height * leg_prop,right_leg = left_leg +rnorm(n, sd =0.02))-> height_legs
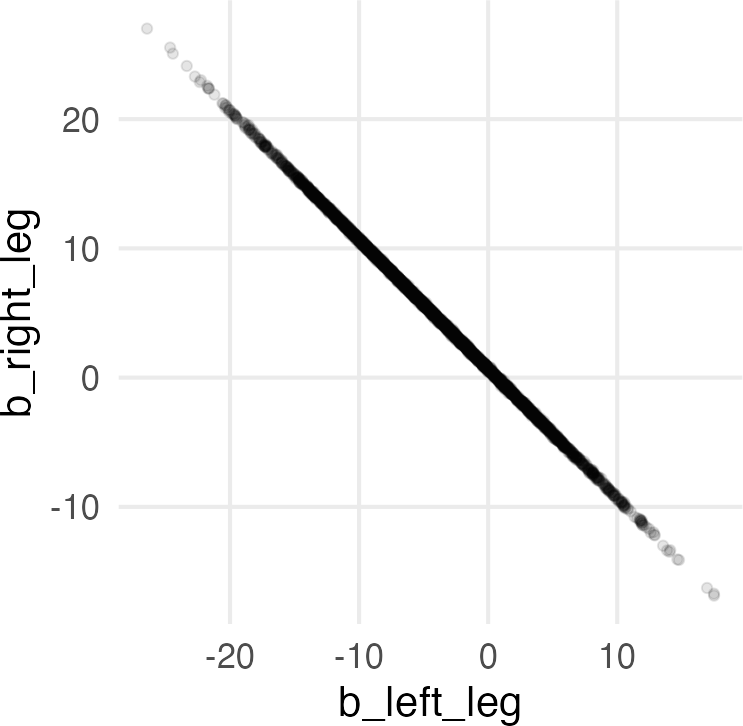
The simulated right leg length is going to be, max, ±0.06 (1⁄16th inch) the left leg.
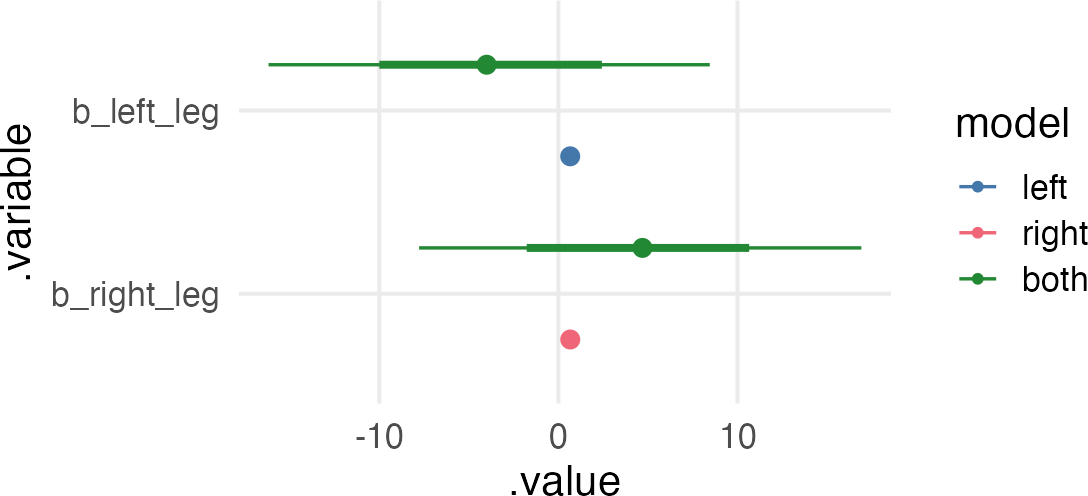
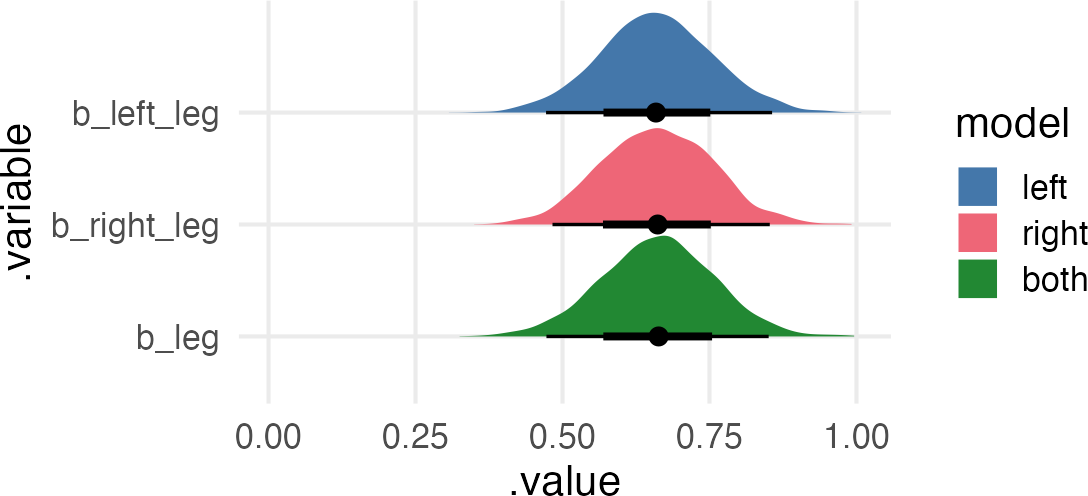
And because there’s nothing else in the model to specify what the value of \(\beta_1\) and \(\beta_2\) are, they’re all over the place. But crucially, they ought to add up to a similar value to what we got for just left_leg and right_leg in the first two models. They also should be negatively correlated, so when one is large and positive, the other should be large and negative, so they cancel out to around the values we got before.
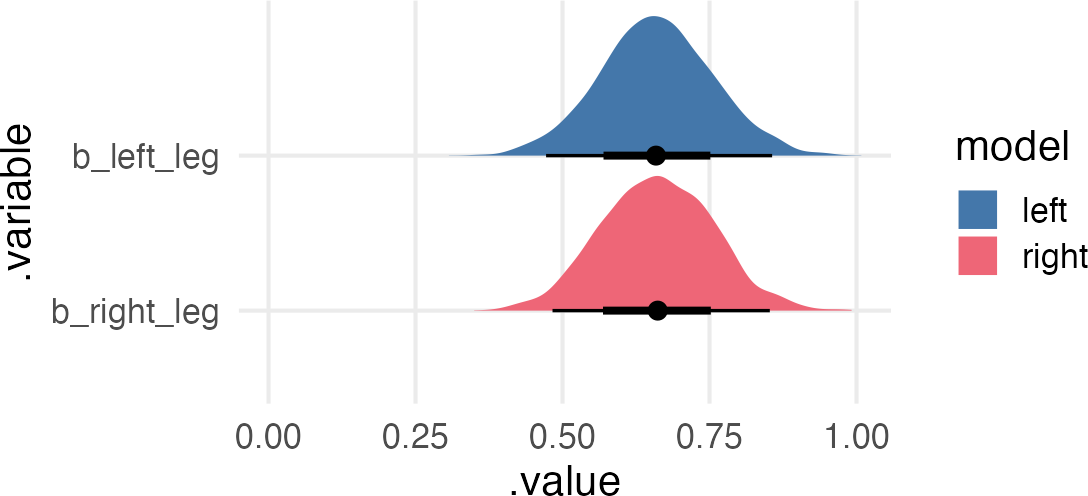
the multicollinear estimates
height_both_mod |>spread_draws(`.*_leg`,regex = T )-> leg_ests
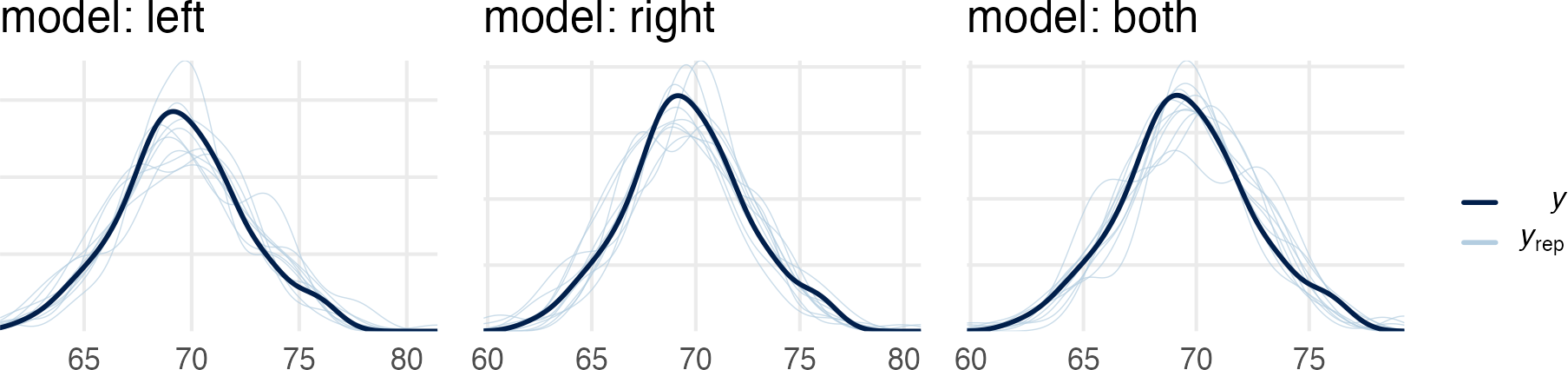
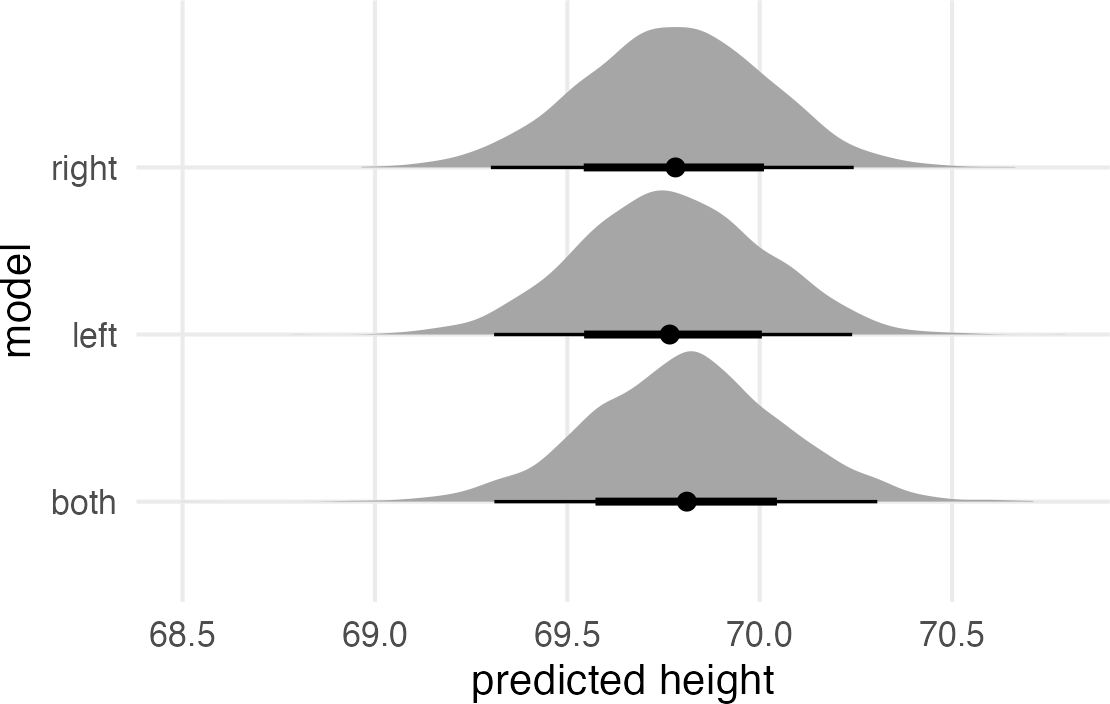
Just to hammer home the point that the predictive value of the multicollinear model, we can compare its posterior predictive checks to the left and right leg models.
all_pred |>ggplot(aes( draw, model ) )+labs(x ="predicted height" )+stat_halfeye()
Figure 7: Predicted heights
So what to do?
The upshot of McElreath’s recommendation for what to do about all this multicollinearity is “have a bad time.” There’s no generic answer. Maybe there’s an acceptable way to specify the model depending on the DAG, but also maybe some questions aren’t well put, like “what are the individual contribution of the left leg and the right leg to total height?”