
r
Last semester, I spent time co-developing some python packages:
So, I thought I’d share a little walkthrough of a cool way to use them. They can both be installed with pip.
bash
pip install fastttrackpy
pip install aligned-textgridFastTrackPy
fasttrackpy (Fruehwald and Barreda 2023) is a python implementation of Santiago Barreda’s Praat plugin (Barreda 2021). Right now, its design is really geared towards command line usage, and has three different subcommands
-
fasttrack audio- This will run fasttrack on a single audio file or a directory of audio files
-
fasttrack audio-textgrid- This will run fasttrack on an (audio, textgrid) tuple
-
fasttrack corpus- This will run fasttrack on a corpus of paired audio + textgrid files
You can check out the docs for all of the processing options. I’ll be using a config file that looks like this:
yaml
# config.yml
corpus: data/corpus/
output: data/results/formants.csv
entry-classes: "Word|Phone"
target-tier: Phone
target-labels: "[AEIOU]"
min-duration: 0.05
min-max-formant: 4000
max-max-formant: 7000
nstep: 20
which-output: winner
data-output: formantsSome of these settings are just the defaults, but I’m just illustrating the kind of things you could do. To run it:
bash
fasttrack corpus --config config.ymlOn my laptop, it got formant estimates for 339 vowels in about 18 seconds.
Looking at the data
Let’s get R up and running
r
vowel_data <- read_csv("data/results/formants.csv")Just to skim over some data columns of interest
r
vowel_data |>
colnames() [1] "F1" "F2" "F3" "F1_s"
[5] "F2_s" "F3_s" "error" "time"
[9] "max_formant" "n_formant" "smooth_method" "file_name"
[13] "id" "group" "label" "F4"
[17] "F4_s"
NoteUseful Columns
- F1, F2, F3, F4
-
The formant tracks as estimated by the LPC analysis
- F1_s, F2_s, F3_s, F4_s
-
Smoothed formant tracks, using discrete cosine transform
- file_name
-
The basename for each file in the corpus
- group
-
If there were multiple talkers annotated in a file, which talker
- id
-
A unique ID for each phone
I’m going to zoom in on my favorite vowel, “AY”, and fit a quick model.
r
r
Model fitting (not the main point)
ay_data |>
group_by(
file_name
) |>
nest() |>
mutate(
model = map(
data,
~gam(
list(F1_s ~ s(prop_time),
F2_s ~ s(prop_time)),
data = .x,
family = mvn(d = 2)
)
),
pred = map(
model,
~predictions(
.x,
newdata = datagrid(
prop_time = seq(0,1,length = 100)
)
)
)
) |>
select(file_name, pred) |>
unnest(pred) |>
select(file_name, rowid, group, estimate, prop_time) |>
mutate(
group = str_glue("F{group}")
) |>
pivot_wider(
names_from = group,
values_from = estimate
)->
ay_predictionsr
Plotting code
library(scales)
log_rev_trans = trans_new(
name = "log_rev",
transform = \(x) -log(x),
inverse = \(x) exp(-x)
)
ay_predictions |>
ggplot(
aes(
F2,
F1
)
)+
geom_path(
arrow = arrow(type = "closed"),
linewidth = 1
) +
scale_x_continuous(trans = log_rev_trans)+
scale_y_continuous(trans = log_rev_trans)+
coord_fixed()+
facet_wrap(~file_name)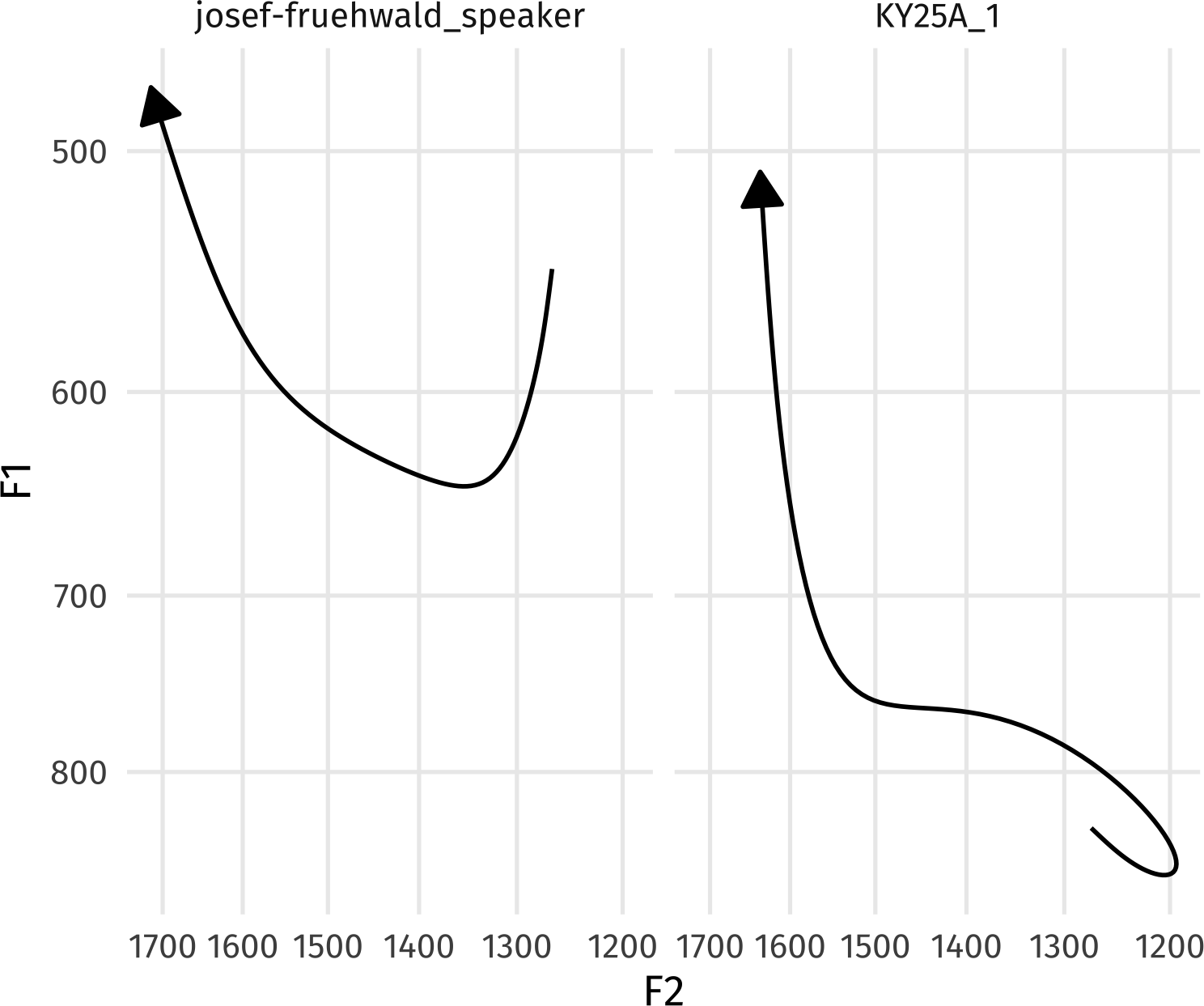
Cool! Except… One of the most important factors for /ay/ is missing: whether or not the following segment is voiced or voiceless! Since fasttrackpy is designed to be very general purpose, (and not too feature laden) this kind of info isn’t added to the output. But. we can easily get it with aligned-textgrid.
Working with aligned-textgrid
Right now, aligned-textgrid (Fruehwald and Brickhouse 2023) mostly designed to be worked with either in scripts, or interactively, so we’re going to switch over to python code. I’ll work over just one TextGrid for clarity.
python
from aligned_textgrid import AlignedTextGrid, Word, Phone
from pathlib import Path
import pandas as pdpython
tg1_path = Path(
"data",
"corpus",
"josef-fruehwald_speaker.TextGrid"
)
tg1 = AlignedTextGrid(
textgrid_path = tg1_path,
entry_classes = [Word, Phone]
)
tg1AlignedTextGrid with 1 groups named ['group_0'] each with [2] tiers. [['Word', 'Phone']]I want to grab out enriched data for each phone for the group_0 speaker, which we can do with the dynamically created accessors for each speaker group and tier class like so.
python
phone_tier = tg1.group_0.Phone
phone_tierSequence tier of Phone; .superset_class: Word; .subset_class: Bottom_wpWe can grab individual phones via indexing.
python
phone_tier[30]Class Phone, label: IY0, .superset_class: Word, .super_instance: the, .subset_class: Bottom_wpBut I want to focus in on just the phones with an AY label, which I’ll do with a list comprehension.
python
ays = [p for p in phone_tier if "AY" in p.label]To grab the following segment for each /ay/, we can use the .fol accessor.
python
# a single example
ays[0].fol.label'T'python
# for all /ays/
[p.fol.label for p in ays]['T', 'K', 'K', 'T', 'T', '#', 'Z', 'N', 'N', '#', 'D', '#', '#', '#', 'D', 'Z', 'Z', 'M', 'D', 'T', 'P']You can see that some /ay/ tokens have a # following segment, meaning a word boundary. If we wanted to get the following segment tier-wise, we can do so to.
python
[p.get_tierwise(1).label for p in ays]['T', 'K', 'K', 'T', 'T', 'AH0', 'Z', 'N', 'N', '', 'D', 'R', 'DH', 'DH', 'D', 'Z', 'Z', 'M', 'D', 'T', 'P']Let’s pop this all into a pandas dataframe
python
ays_context = pd.DataFrame({
"id": [p.id for p in ays],
"fol": [p.fol.label for p in ays],
"fol_abs": [p.get_tierwise(1).label for p in ays],
"word": [p.within.label for p in ays],
"fol_word": [p.within.fol.label for p in ays ]
})
ays_context id fol fol_abs word fol_word
0 0-0-3-4 T T sunlight strikes
1 0-0-4-3 K K strikes raindrops
2 0-0-12-1 K K like a
3 0-0-25-1 T T white light
4 0-0-26-1 T T light
5 0-0-49-1 # AH0 high above
6 0-0-60-2 Z Z horizon
7 0-0-85-1 N N finds it
8 0-0-153-1 N N sign from
9 0-0-188-2 # sky
10 0-0-193-2 D D tried to
11 0-0-209-1 # R by reflection
12 0-0-216-1 # DH by the
13 0-0-235-1 # DH by the
14 0-0-246-0 D D ideas about
15 0-0-263-1 Z Z size of
16 0-0-279-1 Z Z size of
17 0-0-287-2 M M primary rainbow
18 0-0-333-1 D D wide yellow
19 0-0-343-1 T T lights when
20 0-0-354-1 P P type ofWith the way aligned-textgrid links intervals and relates their hierarchical structure, I’m able to quickly able to navigate up, down, and over between intervals using straightforwardly named accessors.
We can get pretty silly, like: what is the second to last phoneme in the word following the word this vowel is in?
python
[
ays[0].label,
ays[0].within.label,
ays[0].within.fol.label,
ays[0].within.fol.last.label,
ays[0].within.fol.last.prev.label
]['AY2', 'sunlight', 'strikes', 'S', 'K']Joining together
Back to the /ays/ data, we can quickly join this enriched data onto the formant data, because the id column is the same between the two.
r
And now I can refit the model and plot.
r
Modelling code
# gam is annoying and needs
# voicing to explicitly be a factor
ays_enriched |>
mutate(voicing = factor(voicing)) ->
ays_enriched
ays_enriched_model <- gam(
list(
F1_s ~ voicing + s(prop_time, by = voicing),
F2_s ~ voicing + s(prop_time, by = voicing)
),
data = ays_enriched,
family = mvn(d = 2)
)
ays_enriched_model |>
predictions(
newdata = datagrid(
prop_time = seq(0, 1, length = 100),
voicing = unique
)
) |>
as_tibble() |>
select(
rowid, group,
estimate, prop_time, voicing
) |>
mutate(
group = str_glue("F{group}")
) |>
pivot_wider(
names_from = group,
values_from = estimate
) ->
ays_enriched_predr
plotting code
ays_enriched_pred |>
ggplot(
aes(
F2,
F1,
color = voicing
)
)+
geom_textpath(
aes(label = voicing),
linewidth = 1,
arrow = arrow(type = "closed")
)+
scale_x_continuous(
trans = log_rev_trans
)+
scale_y_continuous(
trans = log_rev_trans
)+
scale_color_bright(
guide = "none"
)+
coord_fixed()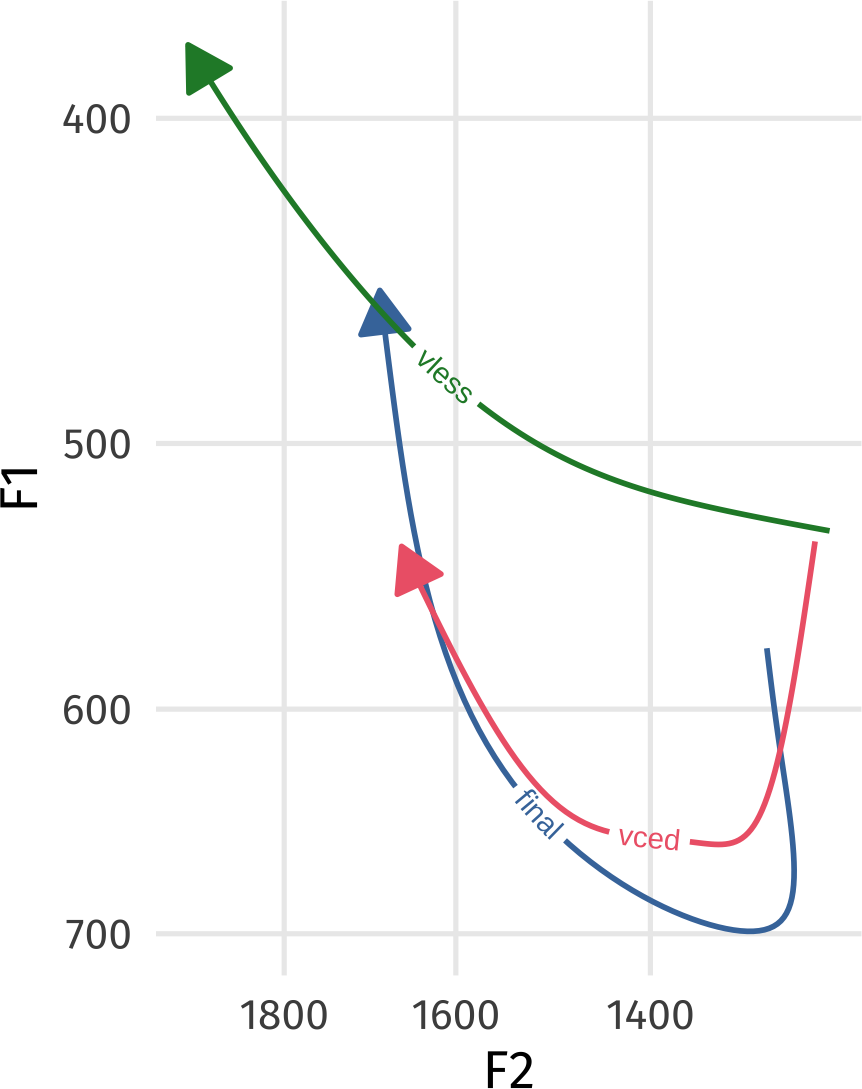
Let me know how it goes!
If you start using either fasttrackpy or aligned-textgrid for any purpose, I’d love to know how it’s going! For any feature requests, or bug reports, checkout their respective github repositories.
References
Barreda, Santiago. 2021. “Fast Track: Fast (Nearly) Automatic Formant-Tracking Using Praat.” Linguistics Vanguard 7 (1): 20200051. https://doi.org/10.1515/lingvan-2020-0051.
Fruehwald, Josef, and Santiago Barreda. 2023. Fasttrackpy. Zenodo. https://doi.org/10.5281/ZENODO.10212099.
Fruehwald, Josef, and Christian Brickhouse. 2023. Aligned-Textgrid. Zenodo. https://doi.org/10.5281/ZENODO.10190692.
Reuse
CC-BY 4.0
Citation
BibTeX citation:
@online{fruehwald2024,
author = {Fruehwald, Josef},
title = {Using {FastTrackPy} and Aligned-Textgrid},
series = {Væl Space},
date = {2024-02-16},
url = {https://jofrhwld.github.io/blog/posts/2024/02/2024-02-16_fs-atg/},
doi = {10.59350/bg6xp-6ch23},
langid = {en}
}
For attribution, please cite this work as:
Fruehwald, Josef. 2024. “Using FastTrackPy and
Aligned-Textgrid.” Væl Space. February 16, 2024. https://doi.org/10.59350/bg6xp-6ch23.