Apply a DCT Smooth to the targeted data
Usage
reframe_with_dct_smooth(
.data,
...,
.token_id_col,
.by = NULL,
.time_col = NULL,
.order = 5,
.rate = FALSE,
.accel = FALSE
)Arguments
- .data
A data frame
- ...
<tidy-select>One or more unquoted expressions separated by commas. These should target the vowel formant.- .token_id_col
<tidy-select>The token ID column.- .by
<tidy-select>A grouping column.- .time_col
A time column.
- .order
The number of DCT parameters to return. If
NA, all DCT parameters will be returned.- .rate
Whether or not to include the rate of change of signal.
- .accel
Whether or not to include acceleration of signal.
Value
A data frame where the target columns have been smoothed using the DCT, as well as the signal rate of change and acceleration, if requested.
Details
This is roughly equivalent to applying reframe_with_dct followed by
reframe_with_idct. As long as the value passed to .order is less than
the length of the each token's data, this will result in a smoothed version
of the data.
Identifying tokens
The DCT only works on a by-token basis, so there must be a column that
uniquely identifies (or, in combination with a .by grouping, uniquely
identifies) each individual token. This column should be passed to
.token_id_col.
Order
The number of DCT coefficients to return is defined by .order. The default
value is 5. Larger numbers will lead to less smoothing when the Inverse
DCT is applied (see idct). Smaller numbers will lead to more smoothing.
If NA is passed to .order, all DCT parameters will be returned, which
when the Inverse DCT is supplied, will completely reconstruct the original
data.
Examples
library(tidynorm)
library(dplyr)
ggplot2_inst <- require(ggplot2)
speaker_small <- filter(
speaker_tracks,
id == 0
)
speaker_dct_smooth <- speaker_small |>
reframe_with_dct_smooth(
F1:F3,
.by = speaker,
.token_id_col = id,
.time_col = t,
.order = 5
)
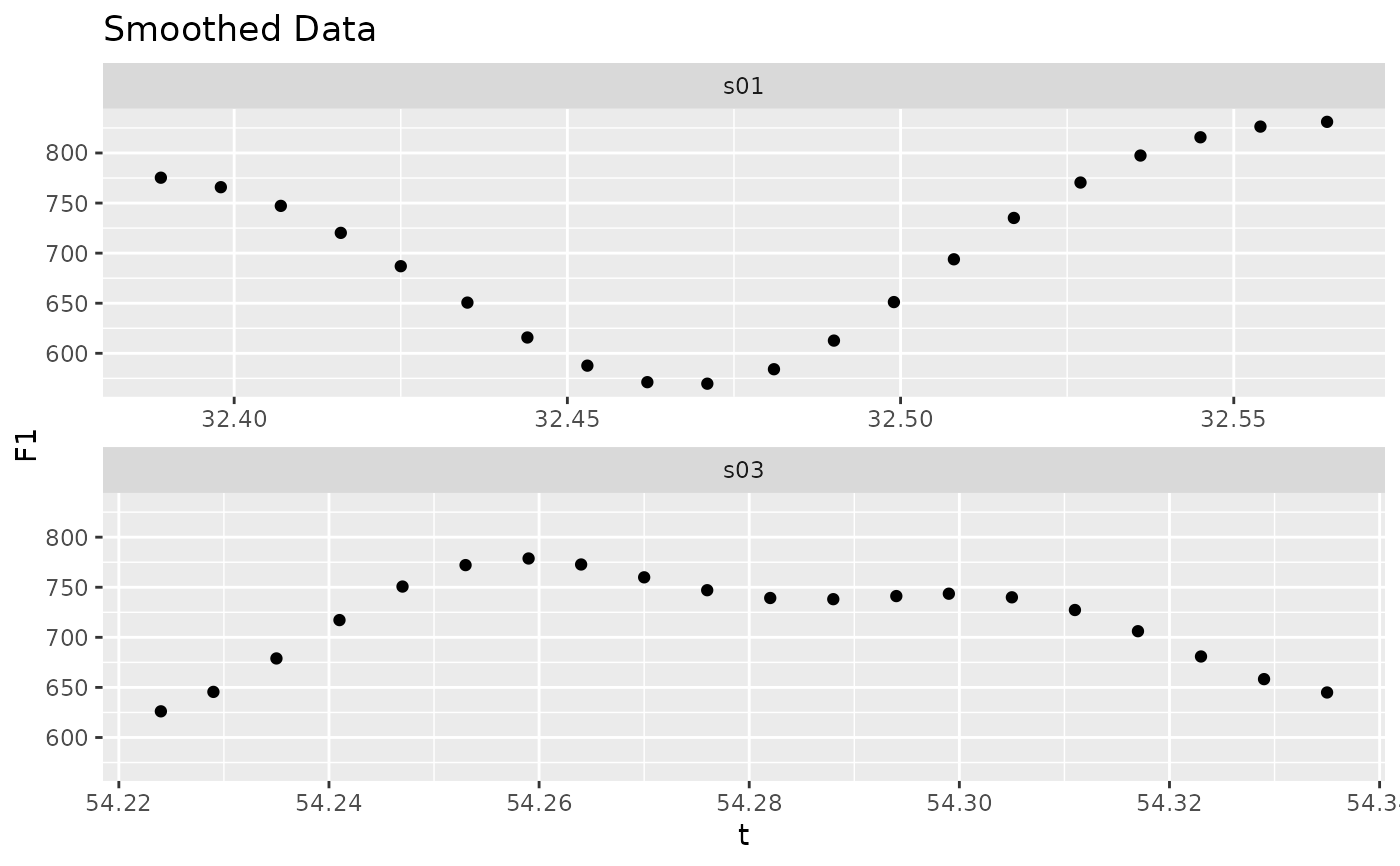
if (ggplot2_inst) {
speaker_small |>
ggplot(
aes(
t, F1
)
) +
geom_point() +
facet_wrap(
~speaker,
scales = "free_x",
ncol = 1
) +
labs(
title = "Original Data"
)
}
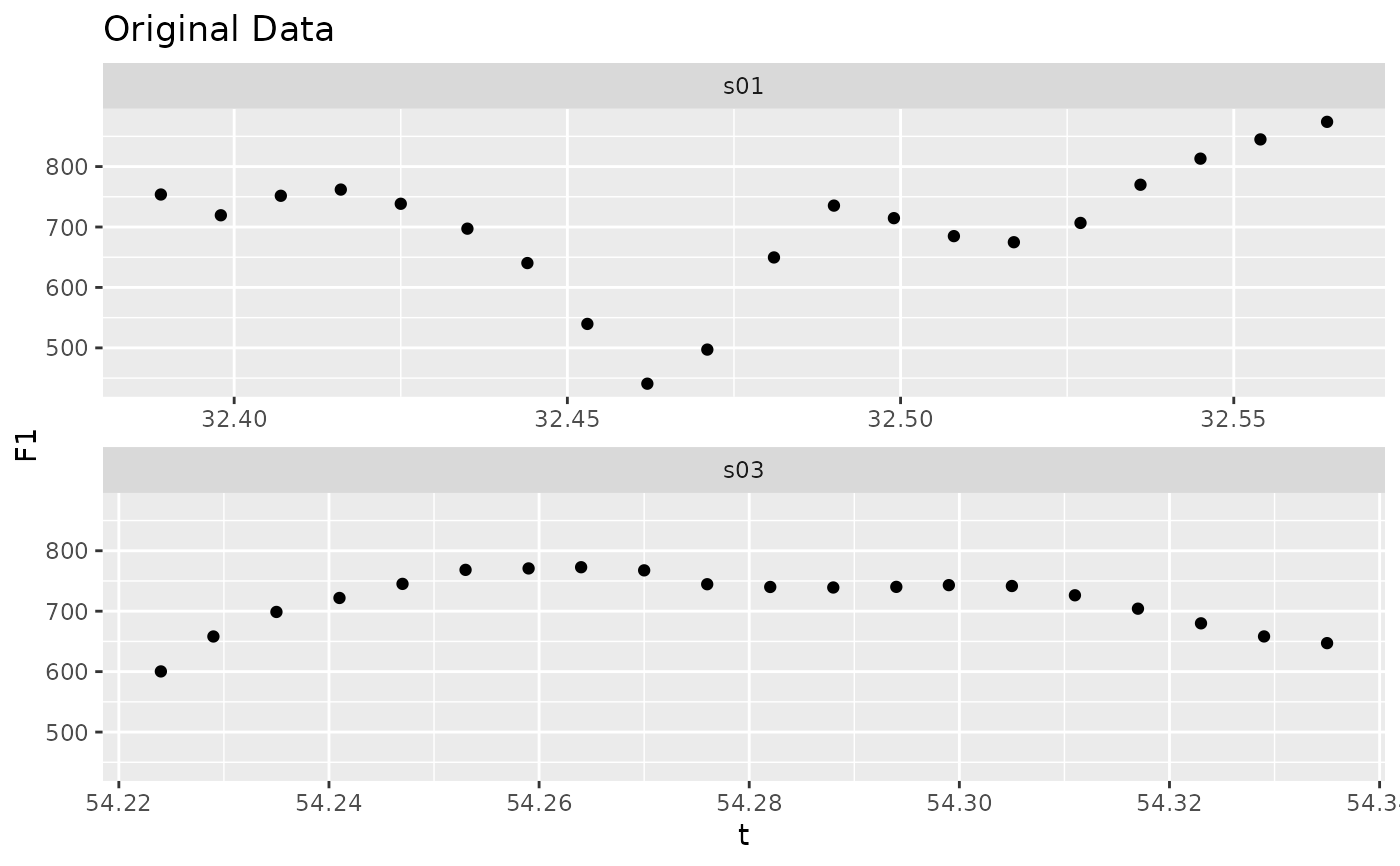 if (ggplot2_inst) {
speaker_dct_smooth |>
ggplot(
aes(
t, F1
)
) +
geom_point() +
facet_wrap(
~speaker,
scales = "free_x",
ncol = 1
) +
labs(
title = "Smoothed Data"
)
}
if (ggplot2_inst) {
speaker_dct_smooth |>
ggplot(
aes(
t, F1
)
) +
geom_point() +
facet_wrap(
~speaker,
scales = "free_x",
ncol = 1
) +
labs(
title = "Smoothed Data"
)
}