Part 1
── Attaching packages ─────────────────────────────────────── tidyverse 1.3.2 ──
✔ ggplot2 3.4.0 ✔ purrr 0.3.5
✔ tibble 3.1.8 ✔ dplyr 1.0.10
✔ tidyr 1.2.1 ✔ stringr 1.4.1
✔ readr 2.1.3 ✔ forcats 0.5.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
x <- read_lines("2022-12-6_assets/input.txt")
input <- tibble(signal = str_split(x, pattern = "")[[1]])
input_lagged <-
input |>
mutate(lag1 = lag(signal, 1),
lag2 = lag(signal, 2),
lag3 = lag(signal, 3),
n = 1:n())
input_lagged |>
drop_na() |>
mutate(sequence = str_c(signal, lag1, lag2, lag3),
len_unique_sequence = map(sequence, ~.x |>
str_split("") |>
simplify() |>
unique() |>
length()) |> simplify()) |>
filter(len_unique_sequence == 4) |>
slice(1) |>
pull(n)
Part 2
I’ve seen the folly of my ways.
chunkup <- function(chunk_size, x){
start_indices = seq(1,length(x)-chunk_size+1)
end_indicies = seq(chunk_size, length(x))
pad <- rep(NA, chunk_size - 1)
out <- map2(start_indices, end_indicies, ~x[..1:..2])
out <- c(pad, out)
return(out)
}
Replicating part 1 just to check
input |>
mutate(
id = 1:n(),
sequences = chunkup(4, signal),
seq_unique_len = map(
sequences, ~.x |>
unique() |>
length()
) |>
simplify()
) |>
filter(seq_unique_len == 4)
# A tibble: 1,903 × 4
signal id sequences seq_unique_len
<chr> <int> <list> <int>
1 w 1300 <chr [4]> 4
2 g 1301 <chr [4]> 4
3 v 1302 <chr [4]> 4
4 z 1303 <chr [4]> 4
5 t 1304 <chr [4]> 4
6 w 1305 <chr [4]> 4
7 p 1309 <chr [4]> 4
8 z 1310 <chr [4]> 4
9 h 1311 <chr [4]> 4
10 p 1316 <chr [4]> 4
# … with 1,893 more rows
Looks good!
input |>
mutate(
id = 1:n(),
sequences = chunkup(14, signal),
seq_unique_len = map(
sequences, ~.x |>
unique() |>
length()
) |>
simplify()
) |>
filter(seq_unique_len == 14) |>
slice(1) |>
pull(id)
Just for Fun
library(ggdark)
library(khroma)
library(showtext)
Loading required package: sysfonts
Loading required package: showtextdb
Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
library(emojifont)
font_add_google(name = "Mountains of Christmas", family = "christmas")
font_add(family = "Noto Emoji", regular = file.path(font_paths()[2], "NotoEmoji-VariableFont_wght.ttf"))
showtext_auto()
theme_set(dark_theme_gray() +
theme(title = element_text(family = "christmas", size = 20)))
Inverted geom defaults of fill and color/colour.
To change them back, use invert_geom_defaults().
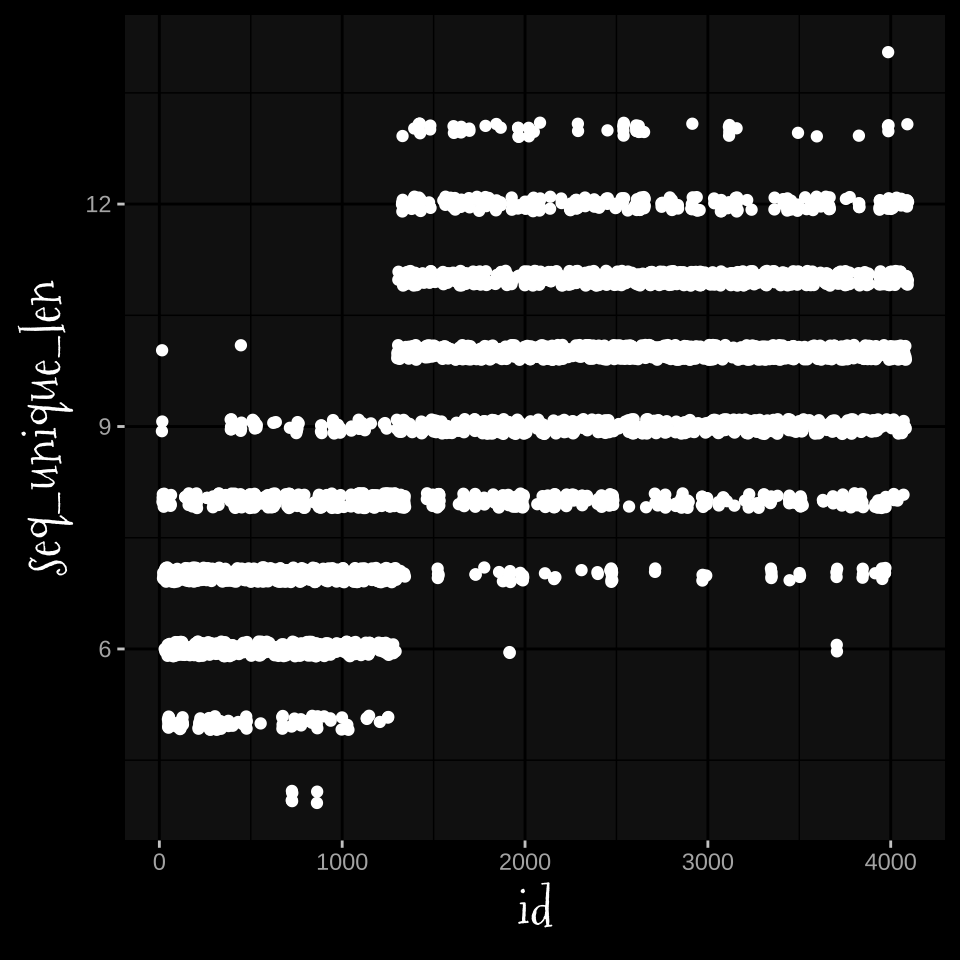
input |>
mutate(
id = 1:n(),
sequences = chunkup(14, signal),
seq_unique_len = map(
sequences, ~.x |>
unique() |>
length()
) |>
simplify()
) |>
slice(14:n()) |>
ggplot(aes(id, seq_unique_len))+
geom_point(position = position_jitter(width = 0, height = 0.1))
sequence_checker <- function(seq_len, df){
df |>
mutate(
id = 1:n(),
sequences = chunkup(seq_len, signal),
!!quo_name(seq_len) := map(
sequences, ~.x |>
unique() |>
length()
) |>
simplify()
) |>
slice(seq_len:n()) |>
select(id, !!quo_name(seq_len)) -> out
return(out)
}
map(4:26, ~sequence_checker(.x, input)) |>
reduce(left_join) |>
pivot_longer(-1, names_to = "seq_len", values_to = "unique_len") |>
drop_na() |>
mutate(prop_unique = unique_len/as.numeric(seq_len)) -> unique_df
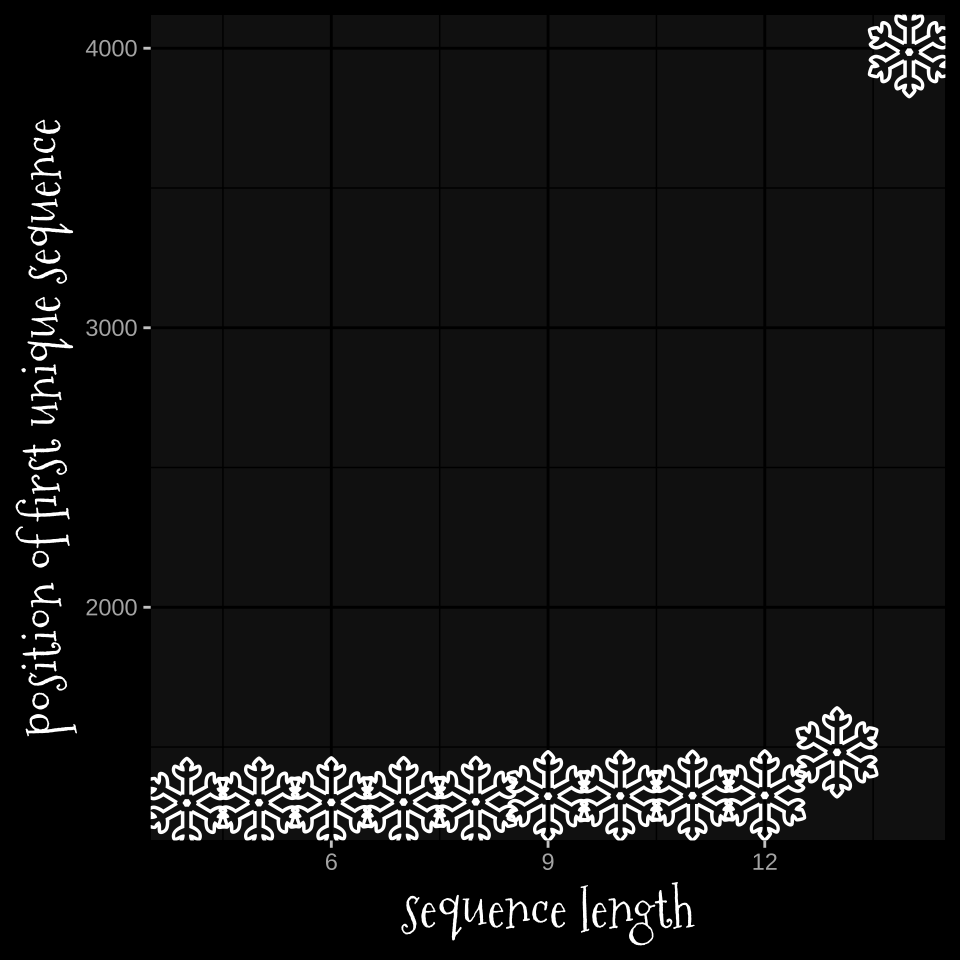
unique_df |>
mutate(seq_len = as.numeric(seq_len)) |>
filter(seq_len == unique_len) |>
group_by(seq_len) |>
slice(1) |>
ggplot(aes(seq_len, id))+
geom_text(label = emoji("snowflake"),
size = 12,
family = "Noto Emoji")+
labs(x = "sequence length",
y = "position of first unique sequence")
Looks like no sequence longer than 14 has a unique run of letters!
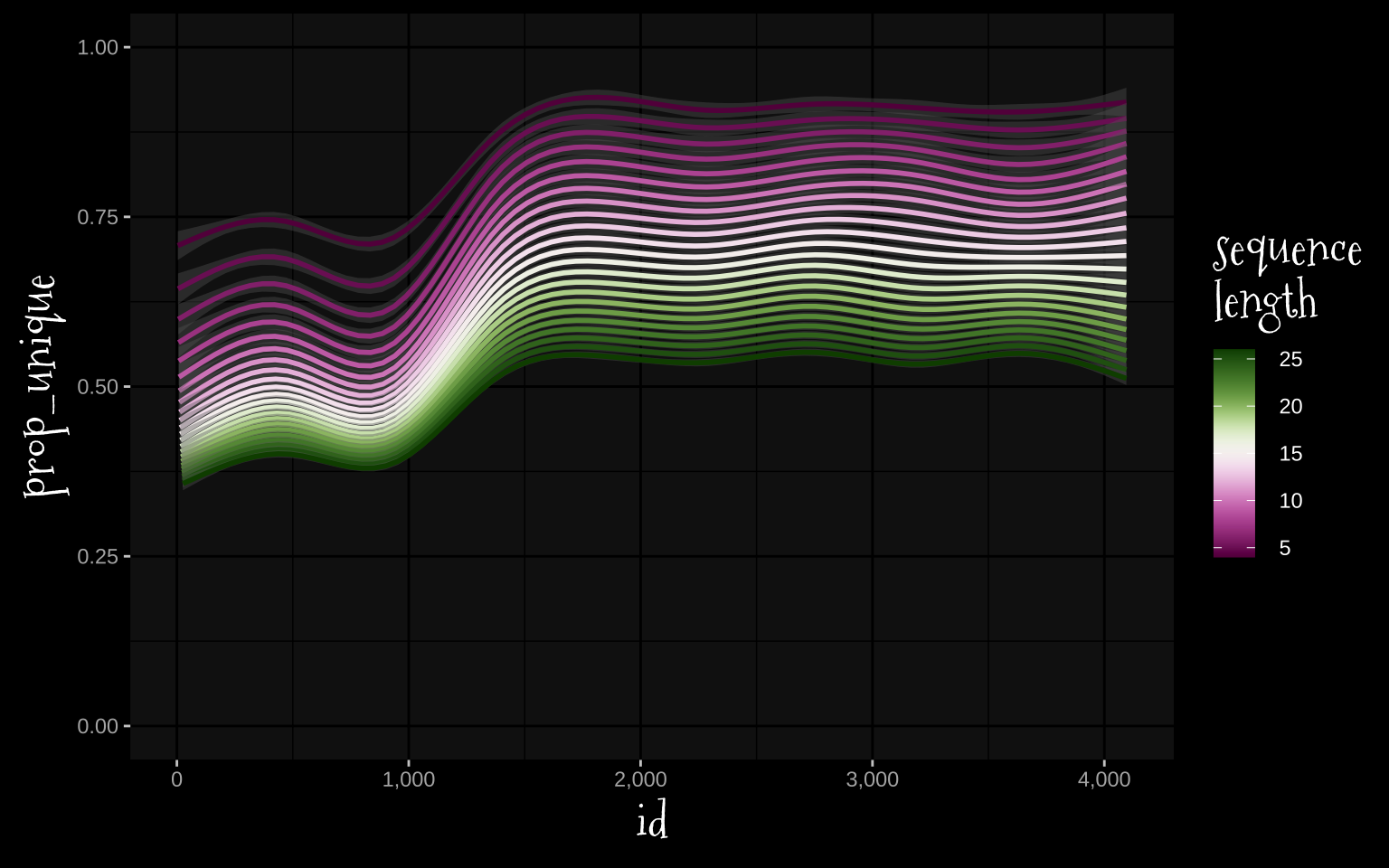
unique_df |>
ggplot(aes(id, prop_unique))+
stat_smooth(aes(group = seq_len, color = as.numeric(seq_len)))+
scale_color_bam(name = "sequence\nlength", midpoint = median(4:26))+
scale_x_continuous(labels = label_comma())+
ylim(0,1)