{gt}
Hello!
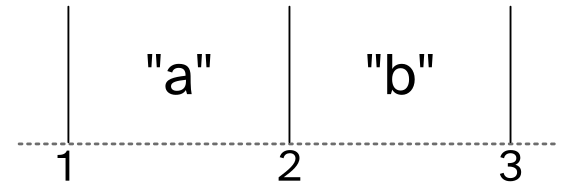
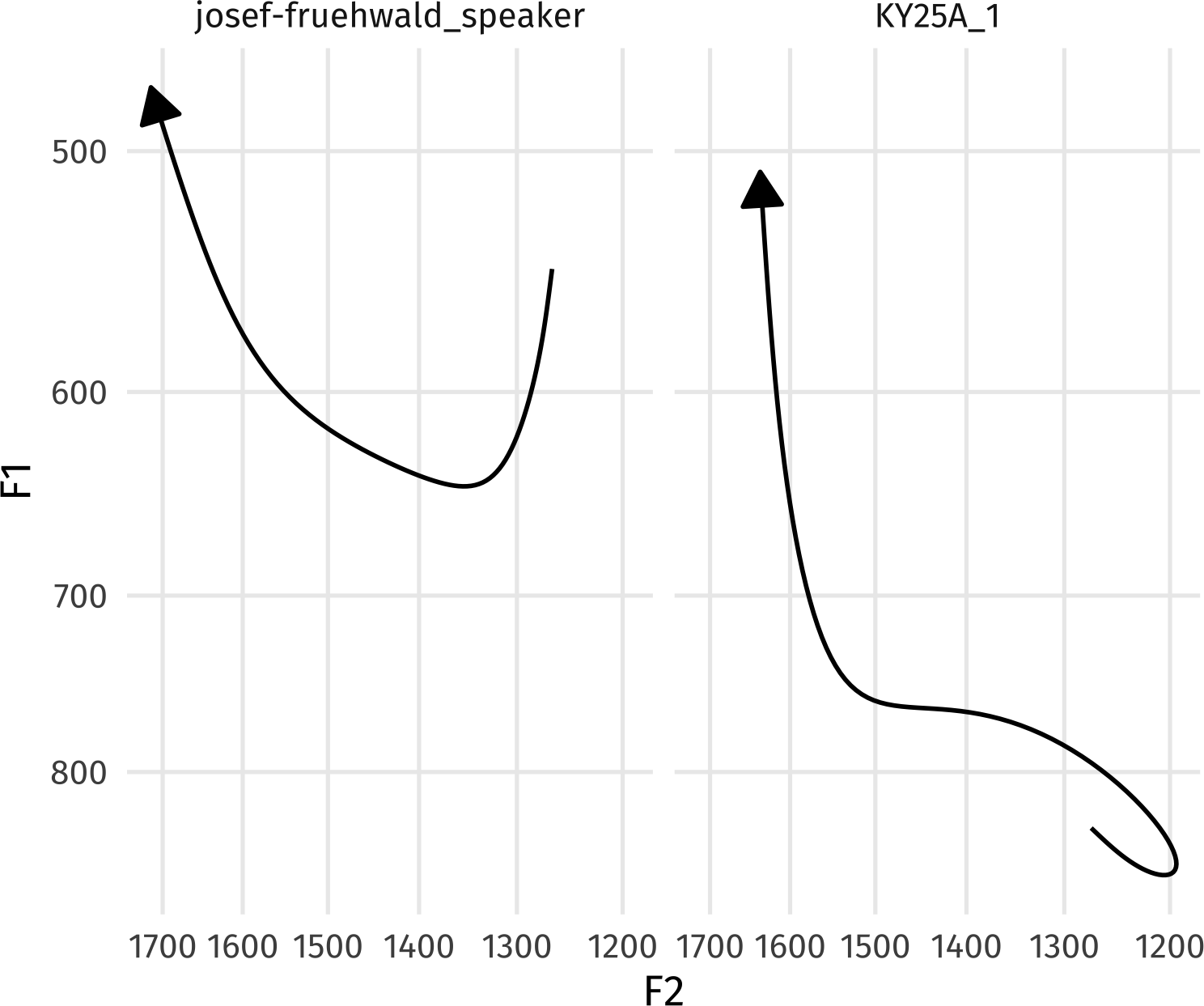
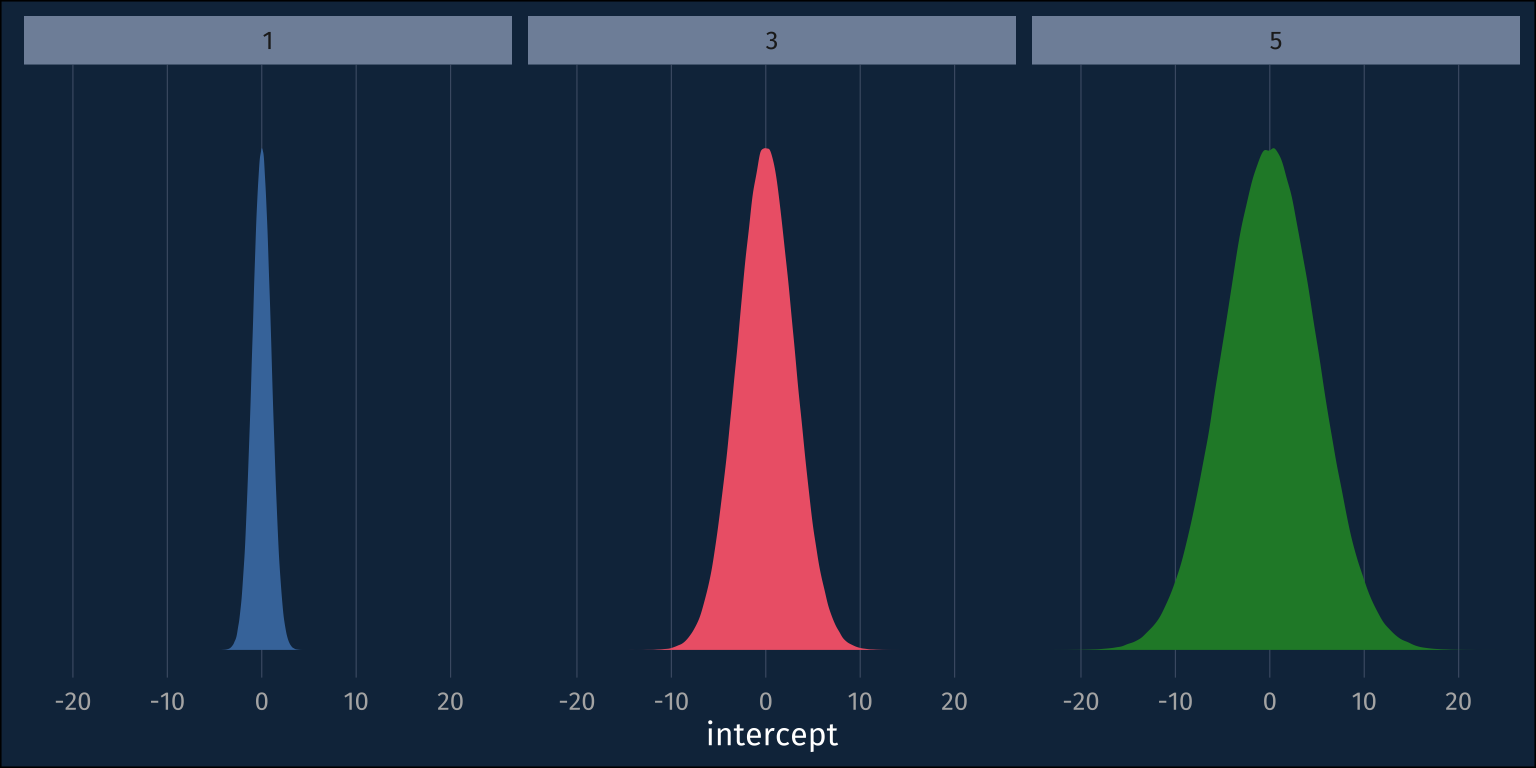
DCT coefficients are really useful!
Here’s a brief introduction to the new {tidynorm} package.
{tidynorm}
.Rprofile
_defaults.R
source(here::here("_defaults.R"))
dplyr::consecutive_id()